Using the Advanced PDF Object
The Advanced PDF object in Advanced Process Automation enables you to capture text from a PDF document using an advanced OCR engine.
To capture text, images must have a resolution of at least 200 dpi, with a contrast of 50% brightness or more.
Each PDF file being loaded cannot be larger than 2GB.
OCR functionality is included in the Advanced PDF object, which can be found in the Direct.Vsd.Library. Use the Advanced PDF object for getting text and tables from the PDF only.
The following languages are supported: Arabic, Armenian, Azeri, Bashkir, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch, Estonian, English, Farsi, Finnish, Dutch, French, German, Greek, Hebrew, Hungarian, Indonesian, Italian, Japanese, Korean, Latin, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, Tatar, Thai, Turkish, Ukrainian, Vietnamese.
Advanced PDF Object Functionality
You can review the available functions of the Advanced PDF object from the Direct.Vsd.Library in the Real-Time Designer.
To view Direct.Vsd.Library functionality:
-
In the Real-Time Designer, select the Project tab.
-
In the Reference section, browse to Library References > Direct.Vsd.Library.
-
In the Functionality tab, from the Type drop-down list, select Advanced PDF.
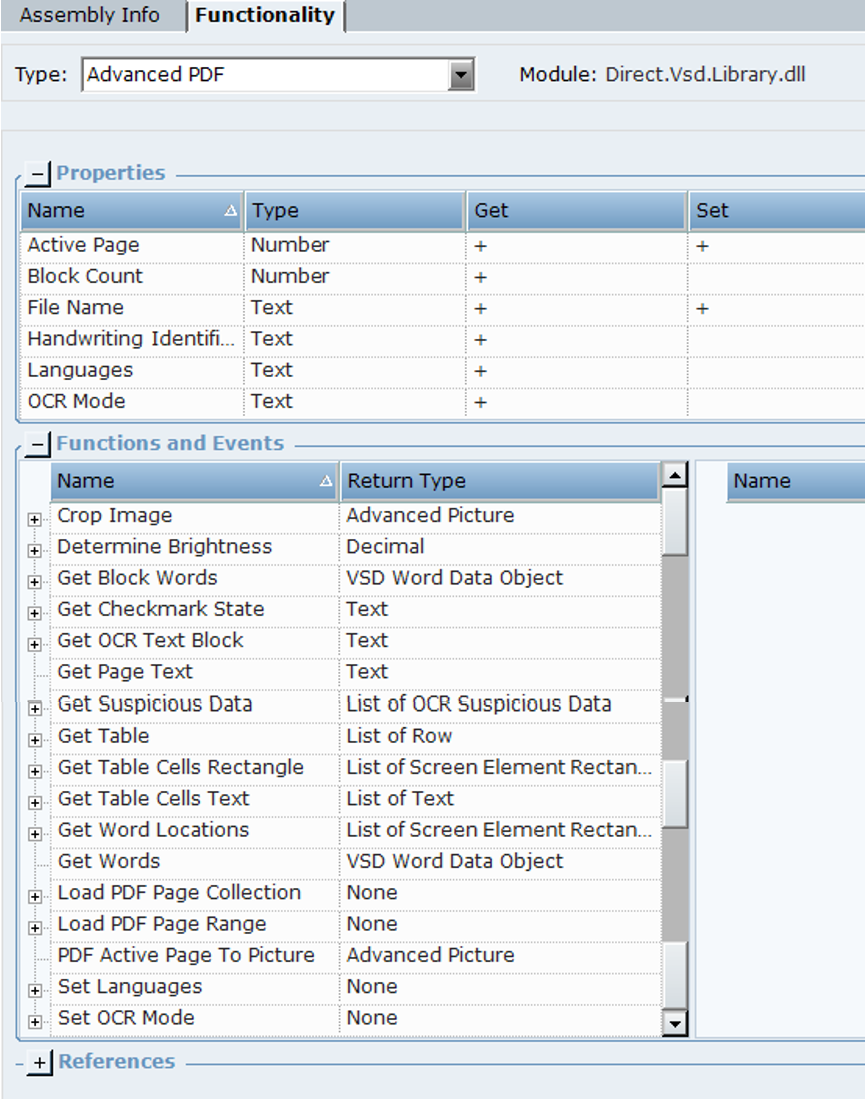
The following properties are available:
|
Property |
Description |
|---|---|
|
Active Page |
The page number of the page in the PDF from which to read data. The default value is 1. |
|
Block Count |
The number of OCR blocks on the Active Page of the document. |
|
File Name |
The full path to the PDF file, for example: C:\Data\Sample1.pdf |
|
Handwriting Identification Mode |
The name of the expected handwriting style of the text, passed as in input to the OCR engine to improve text recognition. Relevant only when OCR Mode is set to Handwriting. |
|
Languages |
The expected language(s) of the text, passed as in input to the OCR engine to improve text recognition. The default is English. |
|
OCR Mode |
The OCR mode to be used by the OCR engine |
|
Pages Count |
The number of pages in the PDF file. |
|
Tables Count |
The number of the recognized tables in the active page. This property gets the number of tables only after the table's data recognition (first run of function to get text from the table, using the known index of the table in advance). |
The following functions are available:
|
Function |
Description |
|---|---|
|
Crop Image |
Retrieve a specified screen element rectangle from the active page of the PDF as an Advanced Picture Object. |
|
Determine Brightness |
Determines a brightness value in percentages of a given area of Advanced PDF object by coordinates (100 is white). |
|
Get Block Words |
Retrieve all words individually from a specified block on the active page of the PDF |
|
Get Checkmark State |
Retrieve the state of the checkbox in a specified rectangle on the active page of the PDF. Returns a text value: Checked, NotChecked, Corrected (was checked but then corrected), or Not Recognized. If OCR is not installed, NotDetected is returned. See Using the OCR Get Checkmark State Function. |
|
Get OCR Text Block |
Retrieve the text from a specified block on the active page of the PDF . |
|
Get Page Text |
Retrieve the text from the active page of the PDF. |
|
Get Suspicious Data |
Retrieve all instances of suspicious data on the active page of the PDF. Optionally check suspicious words against a dictionary. |
|
Get Table |
Retrieve all text from a specified table on the active page of the PDF. Returns a list of rows, where each element of a row stores the text from the corresponding cell of the table. |
|
Get Table Cells Rectangle |
Retrieve the locations of all cells in a table. Returns a list of screen element rectangle objects, where each rectangle specifies the location of one cell. |
|
Get Table Cells Text |
Retrieve all text from a specified table on the active page of the PDF. Returns a list of text, where each element of the list stores the text from one cell of the table. |
|
Get Word Locations |
Retrieve a list of all locations of a specified word on the active page of the PDF. The locations are returned as Screen Element Rectangle objects. See Using the OCR Get Word Location Function. |
|
Get Words |
Retrieve all words individually from the active page of the PDF. |
| Load PDF Page Collection | Preload multiple pages, listed individually by page number, to speed up processing of large files . |
| Load PDF Page Range |
Preload a range of pages, specified by the start page number and number of pages, to speed up processing of large files. |
|
PDF Active Page To Picture |
Populate an Advanced Picture Object variable with an image of the active page of the PDF. |
|
Set Languages |
Set the expected language(s) of the PDF text to improve character recognition. |
|
Set OCR Mode |
Sets the OCR mode used by the OCR engine. If the Default option does not work, you can try one of the following options: Text (Speed): Use this option for a text document where speed is important. Faster than Text(Accuracy), but potentially less exact. Text (Accuracy): Use this option for a text document where accuracy is important. Slower than Text(Speed), but potentially more exact. Document (Speed): Use this option for a text document with objects such as tables where speed is important. Faster than Document(Accuracy), but potentially less exact. Document (Accuracy): Use this option for a text document with objects such as tables where accuracy is important. Slower than Document(Speed), but potentially more exact. Barcode (Speed): Use this option for a barcode where accuracy is important. Slower than Barcode(Speed), but potentially more exact. Barcode (Accuracy): Use this option for a barcode where accuracy is important. Slower than Barcode(Speed), but potentially more exact. Business Cards: Use this option for business cards. Engineering Drawings: Use this option for drawings and charts. One Block: Also called Field Level Recognition. Use this to OCR a single block on the screen. Use this option together controls or with crop functions to demarcate the block. |
{kind=link}